Rincon de las curiosidades (Junio 2023)
Arturo Sirvent Fresneda
Publicado originalmente en la Newsletter: El rincón de los Datos
Hoy hablaremos de un problema común a la hora de sacar conclusiones y relaciones basadas en datos. ¿Quién no se ha preguntado alguna vez: qué habría pasado si hubiera/no hubiera hecho/dicho ___ ? Todo esto es lo que llamamos contrafactuales, y como el tiempo solo fluye en una dirección, y los trenes solo pasan una vez, la respuesta exacta a esas preguntas siempre será hipotética. Sin embargo, sí que podemos intentar aproximarnos a ella, mediante un entorno controlado, y es esto lo que se hace en gran parte de los estudios que se llevan a cabo en sociología, farmacología, etc. Lo podemos resumir en: encontrar relaciones causales entre eventos. Pero, ¿Cómo sabemos que hemos eliminado todas las variables relevantes que podrían confundir nuestras conclusiones? Y es sobre esto de lo que trata el rincón de hoy, sobre las variables confusoras. Estas variables, cuando pasan desapercibidas, son el terror de todo experimento, porque pueden dar lugar a resultados erróneos, y falsas conclusiones (“nos confunden”).
Y no penséis que esto solo afecta a los encargados de diseñar un experimento, a la hora de crear un modelo predictivo, o de analizar datos y buscar relaciones entre ellos, también podemos caer en estas “ilusiones de causalidad”.
Primero de todo veamos que son estas variables confusoras, y después abordaremos el como evitarlas o atenuar su efecto.
Las variables confusoras no son otra cosa que variables externas, que están relacionadas con nuestro input (var. independiente) y output (var. dependiente), y que entorpecen la percepción que tenemos de la relación causal entre ellas.
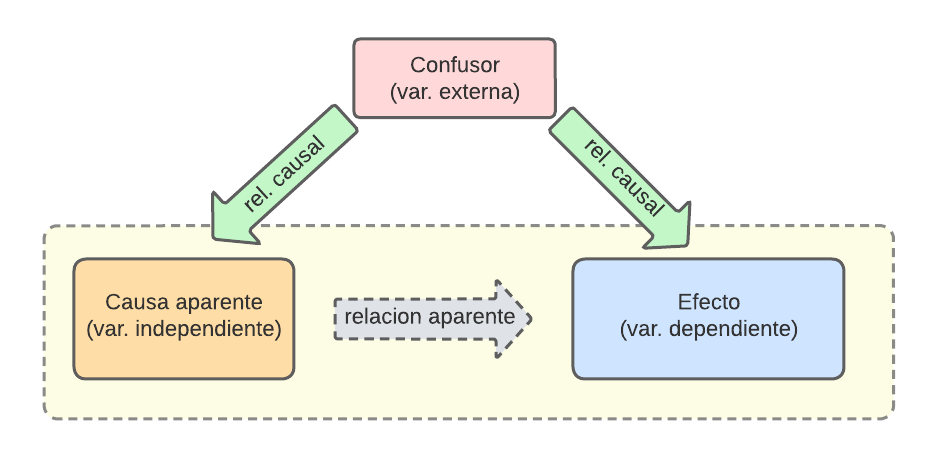
Por poner un ejemplo concreto, si calculáramos la relación entre la gente que lleva un mechero en el bolsillo, y la que contrae cáncer de pulmón, encontraríamos que llevar un mechero en el bolsillo puede ser peligroso y aumentar nuestras probabilidades de enfermar. Sin embargo, es una tercera variable la que las relaciona, y crea esa relación aparente.
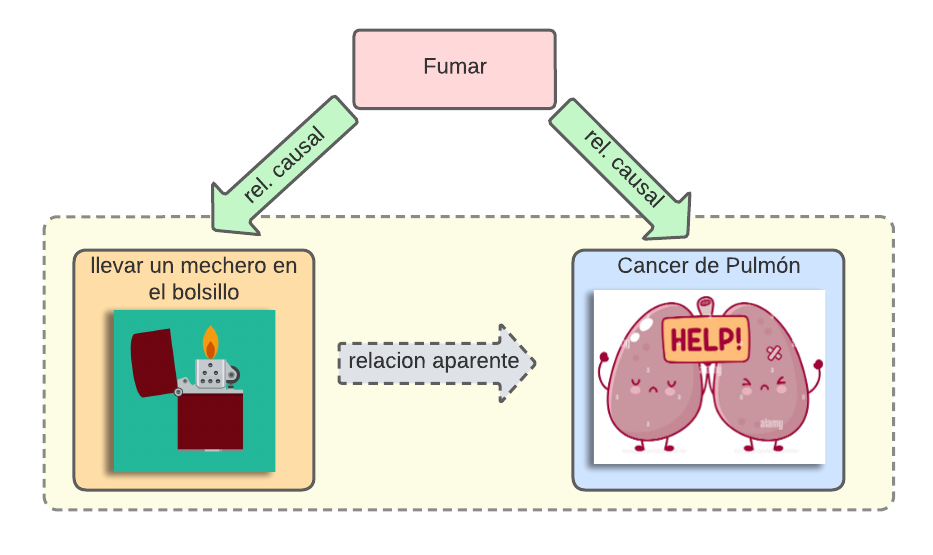
En este ejemplo la causa es muy obvia, pero no siempre estará tan claro.
Si lo pensamos más detenidamente, cuando nuestro objetivo es predecir el output, estas relaciones “aparentes” podrían llegar a resultar útiles. Por dar otro ejemplo, en la película de La Gran Apuesta (The Big Shot), uno de los protagonistas (Christian Bale) es un gestor de fondos y analista de riesgo, que se da cuenta de una serie de relaciones que podrían vaticinar un colapso económico. En concreto, el protagonista observa un aumento de cierto tipo de hipotecas + aumento en la tasas de impagos. ¿Es este hecho, causa directa de una crisis financiera a nivel mundial? No, este solo es otro efecto de una variable confusora “más grande”, que es el estado general de la economía, pero como no podemos medir el estado de la economía en su totalidad, usamos eso a modo de “kpi”. Al observar este aumento de hipotecas + morosidad, el protagonista es capaz de establecer una relación aparente con la posibilidad de una crisis financiera.
Por último, hablemos de como evitar la influencia de confusores en los resultado de un experimento. Una técnica común es intentar que la influencia de estos sea la misma tanto en el grupo de control, como en el grupo de prueba. Homogeneizando la muestra, estamos limitando el posible sesgo.
Y en lo relativo a la construcción de modelos con variables “aparentemente relacionadas”, lo ideal sería contar con conocimiento experto en el tema tratado, para así poder evitar falsas relaciones, y construir modelos con bases causales más robustas.
Y recordemos, correlación no implica causalidad.